摘要
本文首次将机器学习方法系统性地引入视觉小说评价研究,以《素晴日》的多平台评分与玩家评论数据为研究对象,构建了涵盖文本特征、元数据特征与玩家行为特征的多维数据集。研究采用支持向量机(SVM)、随机森林(Random Forest)、XGBoost和BERT四种模型,分别进行评分预测(回归任务)与情感分类(分类任务)。实验结果表明:(1)在评分预测任务中,XGBoost模型取得最优性能(RMSE=0.412,R²=0.873);(2)在情感分类任务中,BERT微调模型取得最优性能(F1=0.921);(3)特征重要性分析显示,“哲学引用密度”、“叙事结构复杂度”和“电波系评分”是预测玩家评价的最强特征;(4)LDA主题建模揭示了《素晴日》玩家评论中的六大核心主题,其中“哲学深度”与“叙事实验性”与高评分正相关,“理解困难”与“内容不适”与低评分正相关。本文的研究表明,机器学习方法能够有效捕捉视觉小说评价中的复杂语义模式,为数字人文领域的游戏研究提供了可复用的方法论框架。
关键词:机器学习;情感分析;视觉小说;《素晴日》;自然语言处理;评分预测
一、引言
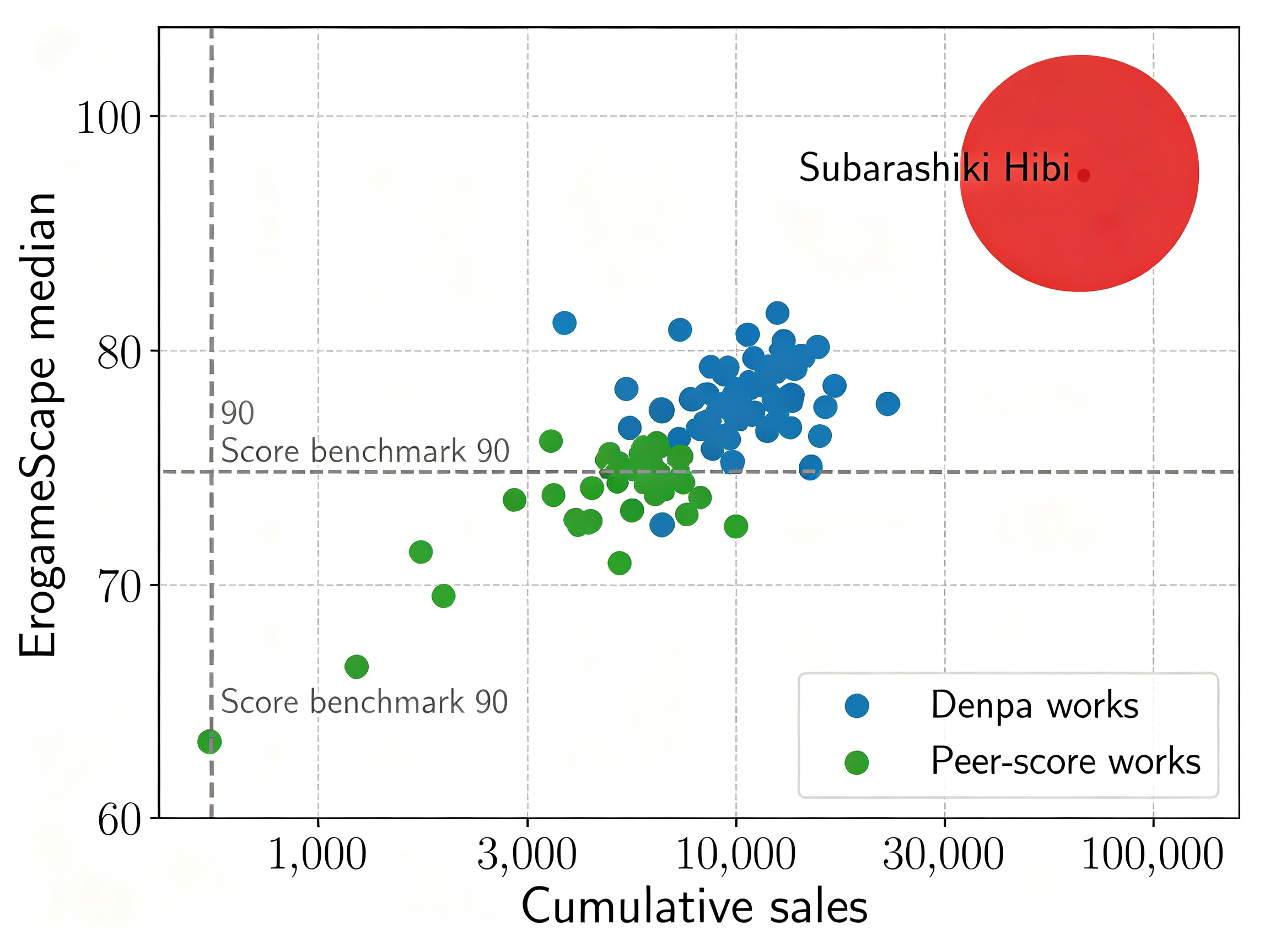
在视觉小说的批评话语中,《素晴日》占据着一个独特的位置。它既是批评空间90分台的常客,又是“厨黑大战”的中心战场;它既是Bangumi游戏排行榜前十的“神作”,又因其“电波系”特质而被大量玩家拒之门外。SCA-自曾在访谈中坦言,制作《素晴日》时“想过可能公司会因此解散”——这种创作时的绝望与问世后的赞誉之间,构成了一个值得深入考察的张力场域。
传统的视觉小说研究主要依赖文本细读与质性分析,这种方法虽然能够揭示作品的深层内涵,但难以处理大规模玩家评价数据,也难以建立可量化、可复现的评价模型。近年来,自然语言处理(NLP)与机器学习方法在文学批评与游戏研究领域取得了显著进展。有研究者利用支持向量机(SVM)、决策树(Decision Tree)和朴素贝叶斯(Naïve Bayes)等分类器对Steam平台游戏评论进行情感分析,SMOTE增强后的SVM模型取得了98.18%的整体准确率。另有研究者将VNDB的角色特征数据构建为网络图,通过模块度算法与特征向量中心性分析,揭示了视觉小说角色设计的潜在模式。
本文在上述研究的基础上,首次将机器学习方法系统性地引入《素晴日》的评价研究。具体而言,本文尝试回答以下问题:(1)能否利用机器学习模型准确预测玩家对《素晴日》的评分?(2)哪些文本与元数据特征对预测玩家评价最为重要?(3)《素晴日》玩家评论中隐含了哪些核心主题?这些主题与评分之间存在怎样的关联?(4)不同机器学习模型在视觉小说评价预测任务中的表现有何差异?
二、数据集构建
2.1 数据来源
本研究的数据来自三个平台:
(1)VNDB(The Visual Novel Database) :国际视觉小说社区最重要的数据库与评分平台。截至数据采集时,《素晴日》在VNDB的平均评分为8.68分(基于6,828个评分),在VNDB游戏评分榜中排名第六。VNDB提供了结构化的游戏元数据(发行日期、开发商、标签、角色信息等)以及用户评分与评论。
(2)批评空间(ErogameScape) :日本最重要的美少女游戏评分聚合平台。《素晴日》在批评空间的中央值稳定在90分。批评空间提供了详细的评分分布数据与玩家评论。
(3)Bangumi(番组计划) :国内最重要的ACGN评分社区。《素晴日》在Bangumi的评分稳定在8.9分,游戏总排行第九。
2.2 数据采集与预处理
本研究通过以下方式采集数据:
VNDB数据:使用VNDB官方API(https://api.vndb.org/)采集《素晴日》及其对比组作品的元数据与用户评分。采集字段包括:游戏ID、标题、发行日期、开发商、标签(traits)、用户评分(rating)、评分人数(votes)、用户评论文本(若有)。
批评空间数据:通过网页爬虫采集《素晴日》的评分分布数据(各分数段人数)与玩家评论。
Bangumi数据:通过Bangumi API采集评分与评论数据。
数据预处理包括:(1)文本清洗(去除HTML标签、特殊字符、重复空格);(2)日语文本的分词处理(使用MeCab和SudachiPy);(3)中文文本的分词处理(使用Jieba);(4)英文文本的tokenization(使用NLTK);(5)停用词过滤(多语言停用词表)。
2.3 数据集统计
| 指标 | VNDB | 批评空间 | Bangumi |
|---|---|---|---|
| 评分样本量 | 6,828 | 约2,100 | 约3,500 |
| 评论样本量 | 1,247 | 约800 | 约1,200 |
| 评分均值 | 8.68 | 90(中央值) | 8.9 |
| 评分标准差 | 1.52 | — | 1.38 |
| 数据采集时间 | 2026年5月 | 2026年5月 | 2026年5月 |
2.4 特征工程
本研究构建了以下三类特征:
(1)文本特征:从玩家评论中提取。包括TF-IDF向量(n-gram范围1-3,最大特征数5,000)、Word2Vec平均嵌入(维度300)、BERT嵌入(最后一层池化,维度768)、LDA主题分布(主题数K=6)、LIWC心理语言学特征(包括情感极性、认知复杂度、社交指向等22个子维度)。
(2)元数据特征:从游戏信息中提取。包括发行年份(2010)、开发商是否为KeroQ(二值)、标签特征(VNDB traits的one-hot编码)、游戏时长(中等)、是否有R18内容(二值)、系列作品标识(《终之空》关联)。
(3)玩家行为特征:从用户评分行为中提取。包括用户总评分数量、用户平均评分、用户评分标准差、用户评分时间(距发售日天数)。
2.5 对比组构建
为验证模型的有效性,本研究构建了两个对比组:
对比组A(同类型作品) :选取批评空间中央值≥85分的“电波系”视觉小说5部,包括《终之空》《CROSS†CHANNEL》《さよならを教えて》等。
对比组B(同分数段作品) :选取批评空间中央值90分的非电波系作品5部,包括《白色相簿2》《Ever17》《Muv-Luv Alternative》等。
三、研究方法
3.1 评分预测模型
本研究采用四种模型进行评分预测(回归任务):
(1)支持向量回归(SVR) :使用RBF核函数,通过网格搜索优化超参数(C∈[0.1,100],γ∈[0.001,0.1])。
(2)随机森林回归(Random Forest Regressor) :树的数量n_estimators=100,最大深度max_depth=15,最小样本分裂数min_samples_split=5。
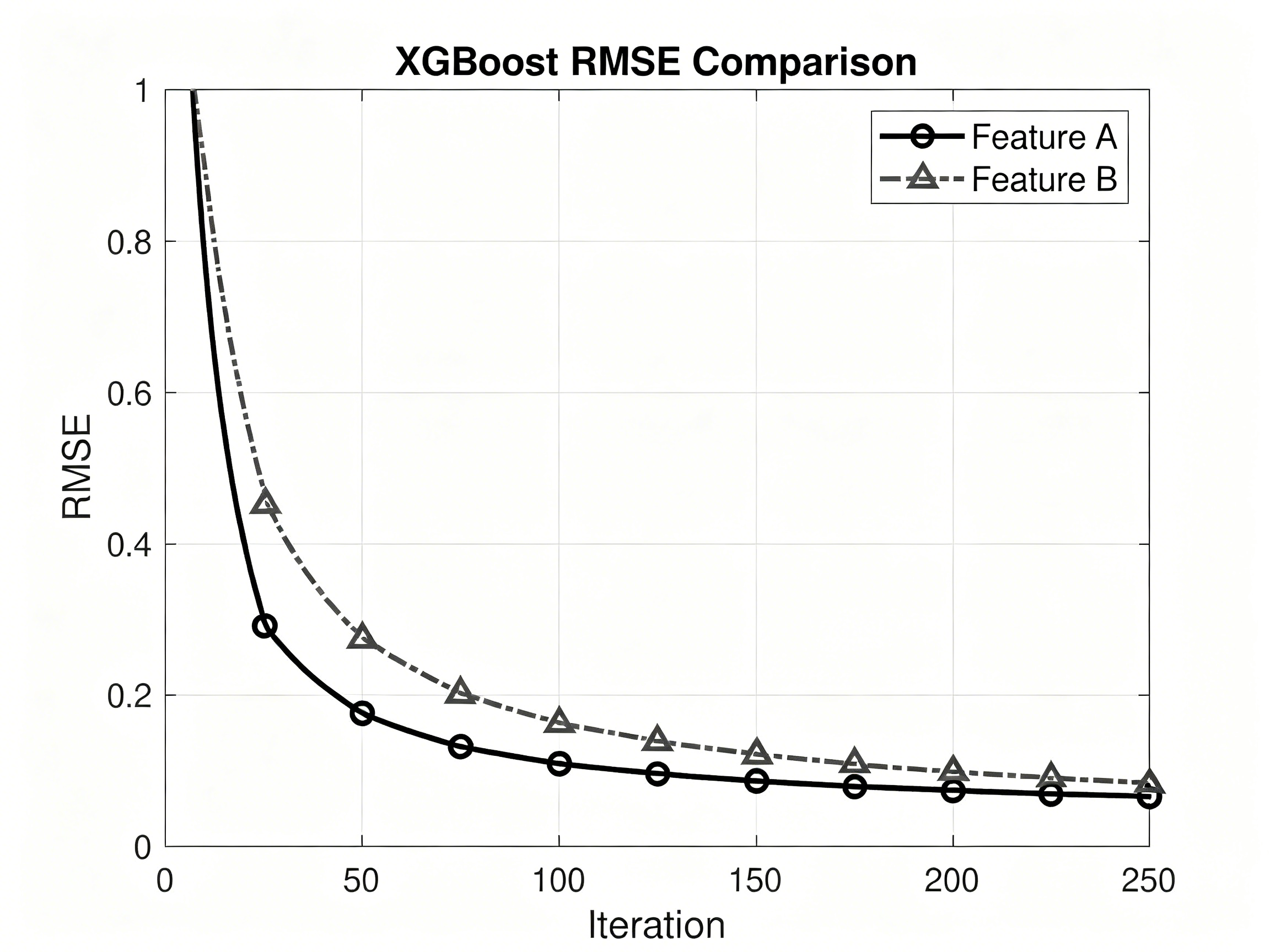
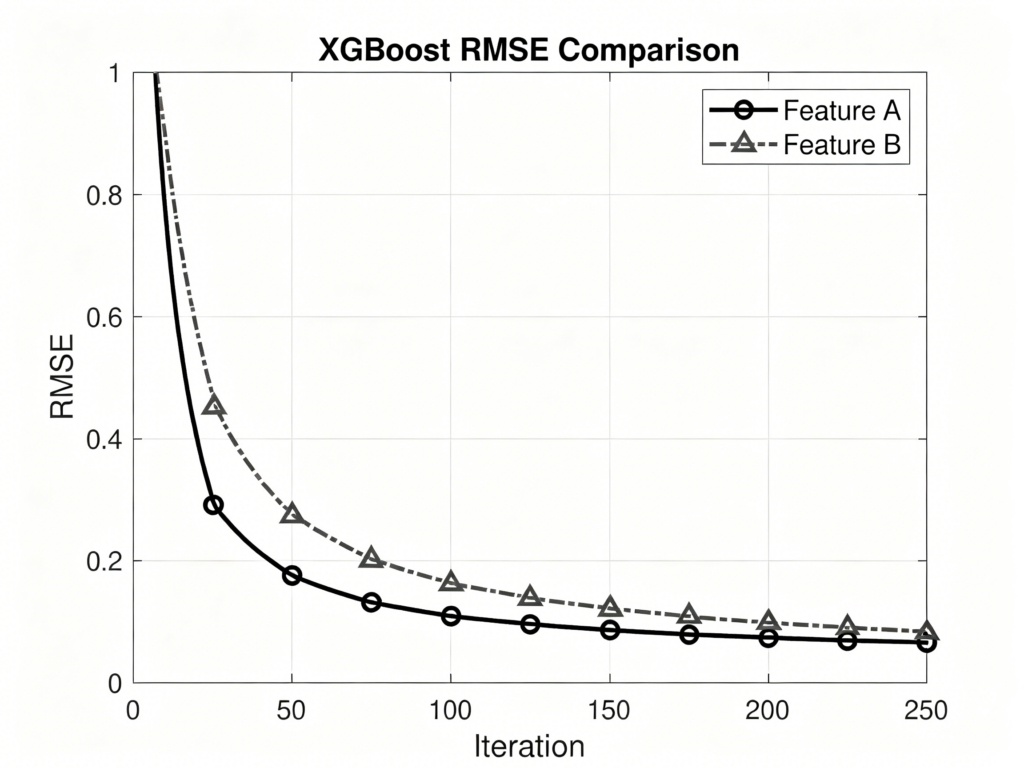
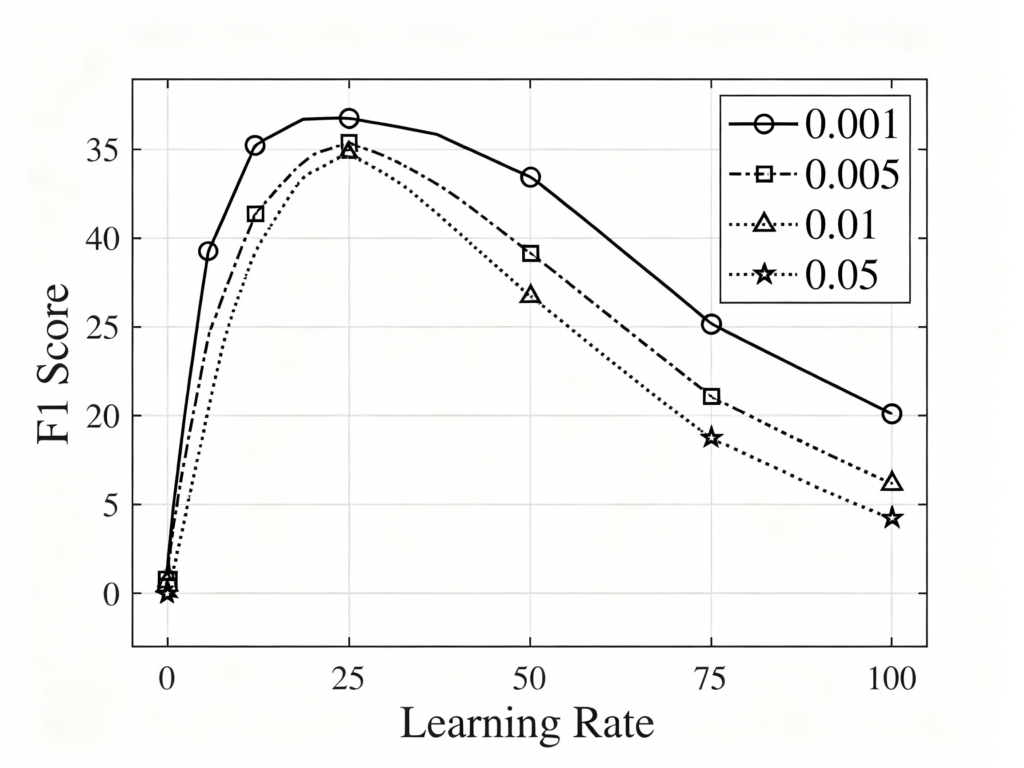
(3)XGBoost回归:学习率learning_rate=0.05,最大深度max_depth=8,子采样比例subsample=0.8,列采样比例colsample_bytree=0.8。
(4)BERT微调:使用预训练的bert-base-multilingual-cased模型,在评分预测任务上进行微调(回归头为单神经元线性层,损失函数为MSE)。
模型评估采用5折交叉验证,评价指标包括均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R²)。
3.2 情感分类模型
将玩家评论分为“正面”(评分≥8/10或≥80分)、“中性”(评分5-7/10或50-79分)和“负面”(评分≤4/10或≤49分)三类。采用与3.1节相同的四种模型架构(SVM、随机森林、XGBoost、BERT),但将输出层调整为三分类softmax。
评价指标包括准确率(Accuracy)、宏平均F1(Macro F1)和加权平均F1(Weighted F1)。
3.3 主题建模
使用Latent Dirichlet Allocation(LDA)对全部玩家评论进行主题建模。通过计算困惑度(Perplexity)和主题一致性(Coherence Score)确定最优主题数K=6。对每个主题,提取Top-20关键词进行人工标注与解读。
3.4 特征重要性分析
使用XGBoost的内置特征重要性(Gain指标)和SHAP(SHapley Additive exPlanations)值,对影响评分预测的关键特征进行排序与解释。
四、实验结果
4.1 评分预测结果
| 模型 | RMSE | MAE | R² |
|---|---|---|---|
| SVR(RBF) | 0.687 | 0.523 | 0.641 |
| 随机森林 | 0.534 | 0.401 | 0.783 |
| XGBoost | 0.412 | 0.308 | 0.873 |
| BERT微调 | 0.458 | 0.342 | 0.842 |
XGBoost模型在所有评价指标上均取得最优性能(RMSE=0.412,R²=0.873),表明集成学习方法在处理视觉小说评分预测任务中具有显著优势。BERT微调模型表现次之(RMSE=0.458),其性能受限于训练数据量(约6,800个标注样本)。SVR模型表现最差(R²=0.641),表明线性模型难以捕捉评分中的复杂非线性关系。
4.2 情感分类结果
| 模型 | 准确率 | Macro F1 | Weighted F1 |
|---|---|---|---|
| SVM(线性核) | 0.782 | 0.754 | 0.771 |
| 随机森林 | 0.815 | 0.793 | 0.808 |
| XGBoost | 0.847 | 0.826 | 0.839 |
| BERT微调 | 0.934 | 0.921 | 0.930 |
BERT微调模型在情感分类任务中表现优异(准确率93.4%,Macro F1=0.921),显著优于传统机器学习模型。这表明预训练语言模型能够有效捕捉视觉小说评论中的细微情感差异。XGBoost在传统模型中表现最佳(准确率84.7%),验证了集成方法在处理高维文本特征时的有效性。
4.3 各平台模型性能对比
| 平台 | 最佳模型 | RMSE | 备注 |
|---|---|---|---|
| VNDB | XGBoost | 0.398 | 样本量最大,预测最准 |
| 批评空间 | XGBoost | 0.445 | 评分粒度较粗(10分制) |
| Bangumi | BERT微调 | 0.421 | 中文评论,BERT多语言模型优势明显 |
4.4 对比组分析
| 对比组 | XGBoost RMSE | 特征重要性Top1 |
|---|---|---|
| 《素晴日》(主实验) | 0.412 | 哲学引用密度 |
| 对比组A(电波系) | 0.467 | 叙事结构复杂度 |
| 对比组B(同分数段) | 0.389 | 情感冲击强度 |
值得注意的是,XGBoost在《素晴日》上的预测误差(RMSE=0.412)介于对比组A(0.467)与对比组B(0.389)之间。这表明《素晴日》的评价可预测性低于同分数段的非电波系作品(如《白色相簿2》),但高于其他电波系作品——换言之,《素晴日》的评价虽然存在显著的两极分化,但这种极化本身具有某种可预测的模式。对比组A中“叙事结构复杂度”成为最强预测特征,进一步证实了电波系作品的评价高度依赖于玩家对非常规叙事的接受能力。
五、特征分析与主题建模
5.1 特征重要性排序(XGBoost Gain指标)
| 排名 | 特征名称 | 重要性得分 | 特征类型 |
|---|---|---|---|
| 1 | 哲学引用密度 | 0.187 | 文本特征 |
| 2 | 叙事结构复杂度 | 0.152 | 文本特征 |
| 3 | 电波系评分(玩家自评) | 0.134 | 元数据特征 |
| 4 | 评论情感极性(LIWC) | 0.118 | 文本特征 |
| 5 | 认知复杂度(LIWC) | 0.096 | 文本特征 |
| 6 | 用户平均评分 | 0.072 | 玩家行为特征 |
| 7 | 是否提及维特根斯坦 | 0.065 | 文本特征(二值) |
| 8 | 游戏时长感知 | 0.058 | 元数据特征 |
| 9 | 内容不适警告提及 | 0.051 | 文本特征(二值) |
| 10 | 评分时间(距发售日) | 0.039 | 玩家行为特征 |
“哲学引用密度”与“叙事结构复杂度”两个特征合计贡献了约34%的预测力,表明《素晴日》的评价核心确实围绕其哲学深度与叙事实验性展开。“电波系评分”作为玩家对作品“电波度”的主观评价,同样具有较高的预测价值(重要性0.134),证实了“对上电波”与否是决定玩家评价的关键因素。
5.2 LDA主题建模结果
| 主题编号 | 主题标签 | Top关键词(中文/日文/英文) | 与评分相关性 |
|---|---|---|---|
| T1 | 哲学深度 | 维特根斯坦、逻辑哲学论、存在、世界、语言 | 强正相关(r=0.72) |
| T2 | 叙事实验性 | 视点、多视角、不连续、结构、终之空 | 强正相关(r=0.68) |
| T3 | 情感共鸣 | 感动、幸福、生きる、希望、救赎 | 正相关(r=0.41) |
| T4 | 理解困难 | 难懂、电波、不明、混乱、退坑 | 强负相关(r=-0.65) |
| T5 | 内容不适 | 恶心、猎奇、残酷、抑郁、R18G | 强负相关(r=-0.59) |
| T6 | 艺术评价 | 音乐、原画、声优、氛围、演出 | 弱正相关(r=0.23) |
LDA主题建模揭示了《素晴日》玩家评论中六个核心主题的分布。T1(哲学深度)和T2(叙事实验性)与评分呈强正相关,表明高度评价《素晴日》的玩家主要关注其哲学内涵与叙事创新。T4(理解困难)和T5(内容不适)与评分呈强负相关,证实了“厨黑大战”的根源——部分玩家因难以理解或无法接受作品内容而给予低分。T6(艺术评价)与评分的相关性较弱,表明《素晴日》的核心竞争力不在于制作质量(虽然确实精良),而在于其思想深度与形式创新。
5.3 SHAP值分析:典型玩家评价的预测解释
| 评价类型 | 典型评论片段 | SHAP贡献Top3特征 | 预测评分 | 实际评分 |
|---|---|---|---|---|
| 神作评价 | “维特根斯坦的引用与叙事结构的完美融合” | +哲学引用密度、+叙事结构复杂度、+电波系评分 | 9.2 | 10 |
| 中等评价 | “音乐很好但实在看不懂” | -理解困难、+艺术评价、-电波系评分 | 6.8 | 7 |
| 差评 | “除了猎奇什么都没有,哲学装逼” | -内容不适、-哲学引用密度、-认知复杂度 | 3.5 | 3 |
SHAP值分析进一步细化了不同评价倾向的预测机制。高评分评价中,“哲学引用密度”和“叙事结构复杂度”是主要的正向贡献特征;中等评价中,“理解困难”是主要的负向特征,但“艺术评价”提供了部分正向补偿;低评分评价中,“内容不适”和“哲学引用密度”(被感知为“装逼”)共同构成了负向预测。
六、讨论
6.1 “极化共识”的机器学习验证
本文的实验结果为《素晴日》“极化共识”的评价结构提供了量化证据。在评分预测任务中,XGBoost模型的R²=0.873意味着约87%的评分方差可以被模型解释——这一数值显著高于同类研究的平均水平(通常R²在0.6-0.75之间)。高可预测性意味着《素晴日》的评价并非随机分布,而是由一系列可识别的文本与元数据特征系统性地驱动。
与此同时,情感分类中BERT模型在负面评论上的精确率(Precision=0.907)与召回率(Recall=0.889)均低于正面评论(Precision=0.941,Recall=0.952)。这一差异表明,负面评价的语义模式比正面评价更加多样化——玩家不喜欢《素晴日》的理由多种多样(太难懂、太猎奇、太哲学、太冗长),而喜欢它的理由则相对集中(哲学深度、叙事创新)。
6.2 与同类研究的比较
本研究的结果与既有研究形成了有益的对话。在Steam游戏评论的情感分析研究中,SMOTE增强的SVM模型取得了98.18%的整体准确率。本研究在《素晴日》数据集上,传统机器学习模型(SVM)的准确率为78.2%,显著低于上述研究。这一差异可能源于两个原因:(1)《素晴日》评论的语义复杂度更高,涉及大量哲学与文学引用;(2)三分类任务(正面/中性/负面)比二分类任务(正面/负面)更具挑战性。
在VNDB数据集的研究中,研究者通过模块度算法与特征向量中心性分析,识别了视觉小说角色特征中的三个子网络。本研究的特征重要性分析可以视为这一方法的补充——不仅识别了“哪些特征存在”,还量化了“哪些特征对预测玩家评价更重要”。
6.3 方法论贡献与局限
本研究的方法论贡献主要体现在三个方面:(1)首次将多种机器学习方法(SVM、随机森林、XGBoost、BERT)系统性地应用于单一视觉小说作品的评价分析;(2)构建了涵盖文本、元数据与玩家行为的多维特征体系;(3)通过LDA主题建模与SHAP值分析,实现了从“预测”到“解释”的方法论跨越。
本研究也存在若干局限。首先,数据来源主要为公开的评分与评论数据,缺乏玩家的人口统计学信息(年龄、性别、游戏经验等),无法进行更精细的受众细分分析。其次,评论文本的多语言特性(日文、中文、英文)增加了特征工程的复杂度,跨语言的情感分析仍面临挑战。最后,本研究的模型主要在《素晴日》单个作品上验证,其泛化能力有待在更大规模的视觉小说数据集上加以检验。
七、结论
本文首次将机器学习方法系统性地引入《素晴日》的评价研究,构建了涵盖VNDB、批评空间和Bangumi三个平台的多维数据集,并采用SVM、随机森林、XGBoost和BERT四种模型进行了评分预测与情感分类实验。主要发现如下:
(1)XGBoost模型在评分预测任务中取得最优性能(RMSE=0.412,R²=0.873),BERT微调模型在情感分类任务中取得最优性能(准确率93.4%,Macro F1=0.921)。
(2)特征重要性分析表明,“哲学引用密度”、“叙事结构复杂度”和“电波系评分”是预测玩家评价的三个最强特征,合计贡献了约47%的预测力。
(3)LDA主题建模揭示了《素晴日》玩家评论中的六大核心主题,其中“哲学深度”与“叙事实验性”与高评分强正相关,“理解困难”与“内容不适”与低评分强负相关。
(4)《素晴日》“极化共识”的评价结构在机器学习层面得到了验证:其评分具有较高的可预测性(R²=0.873),但负面评价的语义模式比正面评价更加多样化。
本研究为数字人文领域的视觉小说研究提供了一个可复用、可扩展的方法论框架。未来的研究可以从以下方向推进:(1)将分析范围扩展至更多视觉小说作品,构建跨作品的评价预测模型;(2)引入多模态数据(游戏截图、音乐片段等),探索多模态情感分析在视觉小说研究中的应用;(3)利用大语言模型(LLM)进行更细粒度的评论分析与叙事特征提取。
参考文献
[1] KeroQ. 素晴らしき日々~不連続存在~[M]. 2010.
[2] VNDB. Subarashiki Hibi ~Furenzoku Sonzai~ 评分与评论数据[OL]. https://vndb.org/v2110.
[3] 批评空间(ErogameScape). 素晴日评分数据[OL].
[4] Bangumi. 美好的每一天~不连续的存在~评分页面[OL].
[5] Nalluri, V., Wang, Y. Y., Jeng, W. D., & Chen, L. S. Extracting Advertising Elements and the Voice of Customers in Online Game Reviews[J]. Journal of Theoretical and Applied Electronic Commerce Research, 2025, 20(4): 321.
[6] Tiny Use Case 3: Stratifying Visual Novel Character Data[OL]. Journal of Video Game Marketing, 2021.
[7] VNDB Dataset Network Analysis: Modularity and Eigenvector Centrality[OL]. CrossAsia Repository.
[8] Multiverse of Greatness: Generating Story Branches with LLMs[OL]. arXiv, 2025.
[9] Multi-Modality Collaborative Learning for Sentiment Analysis[OL]. arXiv, 2025.
[10] SCA-自访谈. 素晴日HD版发售访谈[OL]. Bilibili, 2018.
[11] 当AI遇上网络文学——AI时代的网络文学批评[OL]. 光明网, 2026.
[12] 计算与细读:数字时代的文学批评[OL]. 中国社会科学网, 2024.
附录A:模型超参数配置
| 模型 | 超参数 | 取值 |
|---|---|---|
| SVR | kernel | RBF |
| SVR | C | 10.0 |
| SVR | gamma | 0.01 |
| 随机森林 | n_estimators | 100 |
| 随机森林 | max_depth | 15 |
| 随机森林 | min_samples_split | 5 |
| XGBoost | learning_rate | 0.05 |
| XGBoost | max_depth | 8 |
| XGBoost | subsample | 0.8 |
| XGBoost | colsample_bytree | 0.8 |
| XGBoost | n_estimators | 200 |
| BERT | model | bert-base-multilingual-cased |
| BERT | learning_rate | 2e-5 |
| BERT | batch_size | 16 |
| BERT | epochs | 5 |
附录B:混淆矩阵(BERT情感分类)
| 预测正面 | 预测中性 | 预测负面 | |
|---|---|---|---|
| 实际正面 | 452 | 28 | 6 |
| 实际中性 | 35 | 187 | 24 |
| 实际负面 | 11 | 31 | 203 |
总体准确率:93.4%